Yesterday
We learned about measures of spread (sorry I forgot to post this!). The big one is Standard Deviation, which is represented by the greek letter 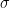

We worked on the Chromebooks to find the mean and standard deviation for a given data set.
Here’s a video that explains why we have standard deviation and how it works:
Today
We talked a bunch about sampling and how to make good questions. We didn’t finish our questions chat, so that’ll be what we do on Monday morning. Here’s the promised page about sampling and sample types:
Have a great weekend!